Finalizamos la serie de entradas de ZIO con la presente entrada, ZIO IV: modulación por capas, en la cual presentaré cómo la librería ZIO permite definir módulos funcionales conectados horizontal o verticalmente. Las entradas publicadas hasta la fecha son las siguientes:

El ejemplo práctico ha realizar consistirá en resolver un problema básico de ingeniero de datos del ámbito de BigData. Todo ingeniero de datos debe de dar solución a una ingesta de datos, transformar los datos conforme a unas reglas de negocio y, para finalizar, almacenar o cargar los datos transformados en un data lake o cualquier tipo de almacén de datos; este proceso, se denomina ETL (Extract, Transform and Load). Así, el caso de uso consiste en realizar un proceso de extracción, transformación y carga de datos solicitado por un actor el cual puede ser un sistema o una persona física.
La solución está compuesta por cuatro elementos: el primero, un módulo con la funcionalidad encargada de la extracción de datos; el segundo, el módulo transformador, encargado de transformar los datos en función de unas reglas de negocio; el tercero, el módulo cargador, encargado de realizar la carga de los datos transformados al almacén de datos; y, para finalizar, el elemento coordinador de las operaciones de los módulos el cual contendrá la definición de las secuencias del programa ETL. En el ejemplo, los procesos de extracción y carga son tareas simbólicas ya que el objetivo del ejercicio reside en el desarrollo de los módulos. Desde un punto de vista gráfico la vista de elementos y los intercambios de mensajes entre ellos queda definido en el siguiente diagrama de secuencia UML siguiente:

El diagrama de secuencia anterior define los elementos que intervienen desde un punto de vista del intercambio de mensajes los cuales son: Extractor, el cual realiza las operaciones de extracción con la función extractData(); Transformed, el cual realiza la transformación de los datos con la función doTransformer(); Loader, el cual realiza las operaciones de carga con la función doLoader(); ModuleLayer, el cual contiene el programa que define las operaciones de coordinación del resto de elementos utilizados en la función run(); y, por último, un actor que activa el inicio de las operaciones.
Una vez identificados las entidades abstractas y el intercambio de mensajes, estamos en disposición de profundizar en los elementos físicos que intervienen en la solución y, para ello, emplearemos un diagrama de clases UML para definir la vista estática de la solución. Así, el diagrama de clases con la arquitectura software es la siguiente:
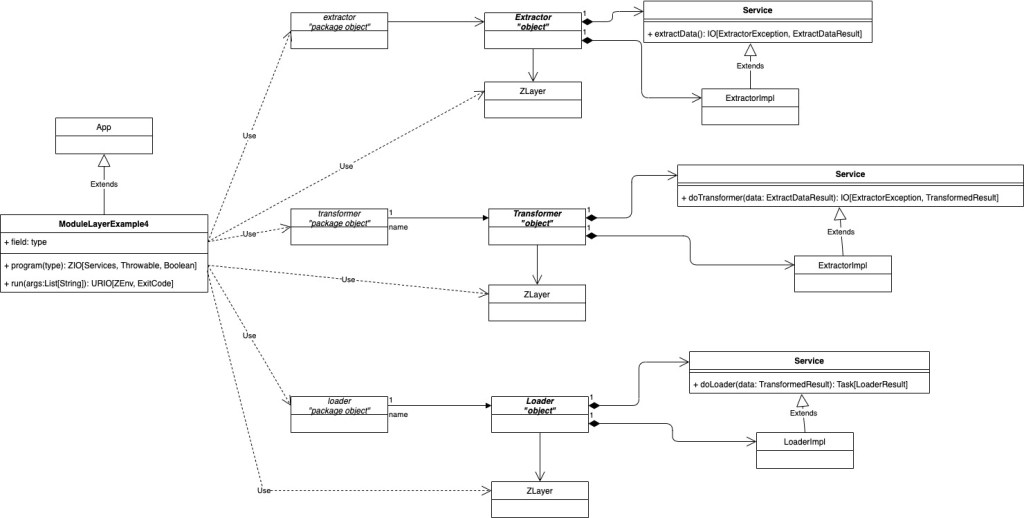
Comenzando en la parte superior del diagrama, tenemos los elementos que definen el extractor. Se define un objeto con nombre Extractor el cual tiene una relación de composición por valor con un trait llamado Service el cual define la operación de extracción con la función extractData; esta función, retorna un elemento de la librería ZIO de tipo IO el cual tiene los siguientes tipos: como valor erróneo, retorna una excepción de tipo ExtractException; y, como retorno de éxito, retorna un ADT de tipo ExtractDataResult. El objeto Extractor tiene un atributo con nombre live el cual define el módulo de ZIO ZLayer asociado a la clase que implementa el servicio ExtractorImpl. Para finalizar, se define un objeto de paquete para enlazar las funciones del objeto Extractor. El snippet del código es el siguiente:
type Extractor = Has[Extractor.Service]
object Extractor {
trait Service {
def extractData(): IO[ExtractorException, ExtractDataResult]
}
case class ExtractorImpl() extends Extractor.Service {
override def extractData(): IO[ExtractorException, ExtractDataResult] =
ZIO.succeed(OkExtract(id = 1, name = "Test1", result = true))
}
val live: ZLayer[Any, Nothing, Extractor] = ZLayer.succeed(ExtractorImpl())
}
[...]
import ModuleLayerExample4Module.Extractor
package object extractor {
def extractData = ZIO.accessM[Extractor](_.get.extractData())
}
Continuando en la parte media del diagrama tenemos los elementos que definen el transformador Transformer. Se define un objeto con nombre Transformer el cual tiene una relación de composición por valor con un trait llamado Service el cual define la operación de transformación con la función doTransformer; esta función, retorna un elemento de la librería ZIO de tipo IO el cual tiene los siguientes tipos: como valor erróneo, retorna una excepción de tipo TransformerException; y, como retorno de éxito, retorna un ADT de tipo TransformedResult. El objeto Transformer tiene un atributo con nombre live el cual define el módulo de ZIO ZLayer asociado a la clase que implementa el servicio TransformedImpl. Para finalizar, se define un objeto para enlazar las funciones del objeto Transformer. El snippet del código es el siguiente:
type Transformer = Has[Transformer.Service]
object Transformer {
trait Service {
def doTransformer(data: ExtractDataResult): IO[TransformedException, TransformedResult]
}
case class TransformerImpl() extends Transformer.Service {
override def doTransformer(data: ExtractDataResult): IO[TransformedException, TransformedResult] =
data match {
case dataIn: OkExtract => ZIO.succeed(OkTransformed(id = dataIn.id, name = dataIn.name, result = true))
case _ => ZIO.fail(BasicTransformedException())
}
}
val live: ZLayer[Any, Nothing, Transformer] = ZLayer.succeed(TransformerImpl())
}
[...]
import ModuleLayerExample4Module.Transformer
package object transformer {
def transformer(data: ExtractDataResult) = ZIO.accessM[Transformer](_.get.doTransformer(data))
}
En la parte inferior del diagrama tenemos los elementos que definen el cargador Loader. Se define un objeto con nombre Loader el cual tiene una relación de composición por valor con un trait llamado Service el cual define la operación de carga con la función doLoader; esta función, retorna un elemento de la librería ZIO de tipo Task con un ADT de tipo LoaderResult. El tipo Task de ZIO es aquel tipo definido para tareas asíncronas. El objeto Loader tiene un atributo con nombre live el cual define el módulo de ZIO ZLayer asocoado a la clase que implementa el servicio LoaderImpl. Para finalizar, se define un objeto de paquete para enlazar las funciones del objeto Transformer. El snippet del código es el siguiente:
type Loader = Has[Loader.Service]
object Loader {
trait Service {
def doLoader(data: TransformedResult): Task[LoaderResult]
}
case class LoaderImpl() extends Loader.Service {
override def doLoader(data: TransformedResult): Task[LoaderResult] =
data match {
case dataIn: OkTransformed =>
ZIO.fromFuture(implicit ec => loaderData(dataIn)).mapError(msg => new ErrorLoaderException())
case _ => ZIO.fail(BasicLoaderException())
}
}
val live: ZLayer[Any, Nothing, Loader] = ZLayer.succeed(LoaderImpl())
}
[...]
import ModuleLayerExample4Module.Loader
package object loader {
def loader(data: TransformedResult) = ZIO.accessM[Loader](_.get.doLoader(data))
}
En la parte izquierda del diagrama, se define el módulo controlador ModuleLayerExample4 con el cual declaramos el programa con las definiciones de las operaciones del proceso ETL. El snippet del módulo es el siguiente:
type Services = Extractor with Transformer with Loader with Logging
// Log layer
val envLog =
Logging.console(
logLevel = LogLevel.Info,
format = LogFormat.ColoredLogFormat()
) >>> Logging.withRootLoggerName("ModuleLayerExample4")
val appEnvironment = envLog >+> Extractor.live >+> Transformer.live >+> Loader.live
def program(): ZIO[Services, Throwable, Boolean] = {
(for {
_ <- log.info("[START]")
dataExtracted <- extractData
_ <- log.info(s"[extrated done] data = ${dataExtracted}")
dataTransformed <- transformer(dataExtracted)
_ <- log.info(s"[transformed done] data = ${dataTransformed}")
dataLoaded <- loader(dataTransformed).catchAllCause(cause => log.info(s"Exception Loader=${cause.prettyPrint}"))
_ <- log.info(s"[loaded done] data = ${dataLoaded}")
_ <- log.info(s"[END]")
} yield { true }) orElse ZIO.succeed(false)
}
override def run(args: List[String]): URIO[ZEnv, ExitCode] = {
(program()
.catchAllCause(cause => putStrLn(s"Exception=${cause.prettyPrint}"))
.exitCode)
.provideCustomLayer(appEnvironment)
}
Lo primero que se define es el tipo Services el cual contiene las funciones a utilizar; en nuestro caso, definimos un tipo con un conjunto de tipos: Extractor, Transforamer, Loader y Logging definidos previamente. El objetivo de este tipo es definir todas aquellas funciones que estarán disponibles en el programa a declarar, en nuestro caso, el programa que declara la funcionalidad del proceso ETL, así, podremos «inyectar» al programa las funciones que necesitemos.
A continuación, se define la referencia al log y al entorno de ejecución del programa, es decir, define aquellos elementos que contienen las implementaciones de las funciones a utilizar.
Para finalizar se define la función que contiene el programa con las operaciones de la ETL. La función retorna un tipo ZIO con la siguiente composición: como entorno de ejecución, tiene un tipo de tipo Services; como tipo de retorno de error define un tipo Throwable; y, como tipo de resultado de éxito, retorna un tipo Boolean.
Dado que el módulo ModuleLayerExample4 es un objeto de la clase zio.App se debe de definir e implementar la función run() la cual realiza la invocación del la función del programa ETL suministrando las capas de los módulos definidas en el elemento appEnvironment.
Al lector interesado puede acceder al código en el siguiente enlace.
La utilización de la librería ZIO permite tener programas modulares, declarativos y seguros. No tenemos que preocuparnos de realizar una inyección de dependencias sino que hay que definir conjunto de tipos con la funcionalidad necesarias la cual utilizaremos en los programas; y, sobre todo, aclarar el proceso de diseño y desarrollo ya que permite definir los componentes o módulos que intervienen en la solución y sus relaciones. Una vez que se tienen claros los módulos y las firmas de los métodos nos permite sin haber desarrollado cada función una estructura de la solución final.