Una de las tareas en todo desarrollo es tener versionado las diferentes versiones de los esquemas de las bases de datos asociados a las versiones del código y su migración de forma automática. Para realizar esta labor, hay varias herramientas; en la presente entrada, me centraré en la herramienta Liquibase.
Liquibase es una solución madura open source para la migración de esquemas de base de datos para desarrollos de aplicaciones. No voy a descubrir una herramienta nueva e innovadora. Mi objetivo en la entrada es realizar unas notas básicas para poder trabajar con ella. Una de las alternativas de Liquibase es Flyway.
Liquibase tiene dos versiones: la versión de la comunidad y la versión enterprise. La versión sobre la que he realizado los ejemplos es con la versión de la comunidad.
Instalación
El proceso de instalación que he realizado es sencillo: he descargado la versión para el sistema de la máquina con la que trabajo (hay versiones para Windows, Linux y Mac), he verificado la versión de la máquina virtual de Java (recomendado la versión 11); y, para finalizar, he descomprimido el fichero; una vez realizado, ya estás en disposición para trabajar con Liquibase.
La estructura de carpetas de Liquibase no es muy amplia. La estructura es la siguiente:
- Carpeta lib.- Contiene las librería y driver preconfigurados.
- Carpeta licenses.- Contiene las licencias de Liquibase.
- Carpeta examples.- Contiene los ejemplos de la documentación.
Además, en la raíz de la carpeta Liquibase, contiene un conjunto de ficheros que van desde ficheros ejecutables a ficheros de texto.
Conceptos
La forma de trabajar con Liquibase consiste en realizar lo siguiente:
- Creación de los ficheros con las operaciones de base de datos.
- Ejecutar Liquibase con el fichero de la operaciones de base de datos. Evidentemente, con la configuración de una base de datos determinada.
- Comprobación en base de datos de los cambios definidos en las operaciones.
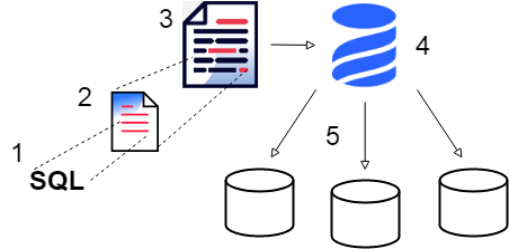
El fichero con las operaciones de base de datos se denomina fichero de changelog en el cual se definen las operaciones de base de datos; estas operaciones, representan un changeset. Así, un fichero changelog está compuesto por un conjunto de changeset las cuales representan las operaciones.
Los ficheros changelog pueden estar definidos en varios formatos: JSON, XML, YAML o bien SQL. Los ejemplos de los siguientes apartados los realizaré en formato SQL.
Desde un punto de vista visual los elementos de Liquibase quedan descritos en la siguiente imagen:
Liquibase necesita conocer la base de datos a la que se tiene que conectar así como las credenciales de la misma. Para almacenar esta información, se define un fichero de properties con los datos necesarios para la conexión y la configuración. La ubicación del fichero de propiedades está en la carpeta raíz de Liquibase.
Ejemplos prácticos
Liquibase puede trabajar con varios tipos de base de datos; por ejemplo: H2, MySQL, PostgreSQL, Microsoft SQL Server,… Los ejemplos de los siguientes apartados los realizaré en una base de datos Microsoft SQL Server.
Para trabajar en local, he descargado una imagen Docker con Microsoft SQL Server, he arrancado un contenedor con la imagen descargada y he creado una base de datos de prueba.
El driver de Microsoft SQL Server no está en la instalación de Liquibase con lo cual, es necesario realizar la descarga del driver y el copiado del fichero jar en la carpeta de Liquibase.
Una vez arrancada la base de datos e instalado el driver de la base de datos en Liquibase, necesitamos configurar Liquibase para que se pueda ejecutar los changelog de los ejemplos en la base datos. Para realizar la configuración, crearemos un fichero de propiedades de la carpeta raíz de Liquibase con nombre liquibase.properties. El contenido del fichero es el siguiente:
changeLogFile:<PATH_AL_FICHERO_CHANGELOG>
liquibase.command.url: jdbc:sqlserver://localhost:1433;databaseName=<NOMBRE_BASE_DE_DATOS>
liquibase.command.username: sa
liquibase.command.password: <PASSWORD>
classpath: mssql-jdbc-10.2.0.jre11.jar
liquibase.hub.mode=off
Ejemplo1: changelog con un fichero
El primer ejemplo consistirá en definir un changelog sencillo formado por un conjunto de changeset en los cuales se define un par de tablas y unas modificaciones sobre las mismas.
El fichero changelog definido es el siguiente:
--liquibase formatted sql
--changeset ams.caso_uso_1:1
create table person (
id int primary key,
name varchar(50) not null,
address1 varchar(50),
address2 varchar(50),
city varchar(30)
)
--rollback DROP TABLE person;
--changeset your.name:2
create table company (
id int primary key,
name varchar(50) not null,
address1 varchar(50),
address2 varchar(50),
city varchar(30)
)
--rollback DROP TABLE company;
--changeset other.dev:3
alter table person add country varchar(2)
--rollback ALTER TABLE person DROP COLUMN country;
--changeset ams.caso_uso2:1
alter table person add other_field varchar(2)
--rollback ALTER TABLE person DROP COLUMN country;
La primera línea del fichero changelog define el formato del fichero. En nuestro case definimos que el changelog está definido en SQL.
Las siguientes partes del fichero están compuestas por changeset. Los changeset deben de tener definidos un autor y un número de orden, normalmente, un número secuencial para cada autor. Para el primer changeset, el nombre del autor es ams.caso_uso_1 y, el número de orden, lo representa el número uno.
Los changeset, en formato SQL, finalizan con el elemento rollback el cual define la política de rollback para el changelog definido. Este tema se abordará en el apartado de rollback.
Una vez definido el changelog, podemos ejecutar Liquibase para que se realizan los cambios en base de datos. El comando a ejecutar si el fichero changelog está en la carpeta raíz de Liquibase es el siguiente.
El resultado por consola de comandos es un listado de los changeset ejecutados. Si existe algún error Liquibase no se ejecuta. El resultado en base de datos es el siguiente:
- Creación de la tablas DATABASECHANGELOG y DATABASECHANGELOGLOCK. Estas tablas son aquellas tablas en donde Liquibase va almacenando la información de los despliegues. En la tabla DATABASECHANGELOG se almacena el campo autor e id, respectivamente, valores definidos en cada changeset; nombre del fichero del changelog ejecutado, fecha ejecución y otros campos de ejecución.
- Creación de las tablas en base de datos.
Una segunda forma de ejecutar Liquibase es pasándole los parámetros de configuración de base de datos desde la línea de comandos.
Ejemplo 2: changelog con N ficheros
Supongamos que tenemos definidos varios ficheros changelog y queremos que estén definidos en nuestra migración porque representan N operativas. La solución consiste en definir un changelog que indique la ubicación de los ficheros de changelog; estos changelog, deben de estar almacenados en una carpeta.
Supongamos que tengamos dos ficheros de changelog en una carpeta sql dentro de Liquibase. Los ficheros son ejemplo2-db-changelog.sqlserver.sql y ejemplo3-db-changelog.sqlserver.sql. El contenido
de los ficheros es análogo al ejemplo anterior.
El fichero changelog necesario con la indicación del conjunto de ficheros sql debe de ser un fichero changelog definido en XML. El contenido del fichero xml con nombre multiple-file-db-changelog-sqlserver.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:pro="http://www.liquibase.org/xml/ns/pro"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-4.4.xsd
http://www.liquibase.org/xml/ns/pro http://www.liquibase.org/xml/ns/pro/liquibase-pro-4.5.xsd">
<includeAll path="sql" />
</databaseChangeLog>
En el snippet anterior se define una etiqueta raíz con nombre databaseChangeLog y, dentro de esta, la etiqueta includeAll la cual indica que en este changelog debe de incluir todo aquello que se encuentra ubicado en el path definido.
En el atributo changeLogFile del fichero liquibase.properties se debe de definir el fichero multiple-file-db-changelog-sqlserver.xml
De la misma manera que el ejemplo anterior , ejecutamos el comando liquibase update para realizar los cambios en base de datos. El resultado por consola y en base de datos sigue el mismo criterio.
Ejemplo 3: changelog con procedimientos almacenados y vistas
Supongamos que queremos definir un procedimiento almacenado o una vista. Con Liquibase, podemos realizarlo si definimos el procedimiento y la vista en un changeset. Un ejemplo de un changeset con un procedimiento y una vista en un changelog determinado es el siguiente:
[...]
-- changeset ams:5
CREATE PROCEDURE prueba.sp_insert_denominador
AS
BEGIN
INSERT INTO prueba.person
(id, name, address1, address2, city)
VALUES
(1, 'name_test1', 'address_test1', 'address_test1', 'city_test1')
END
--rollback DROP PROCEDURE IF EXISTS prueba.person
-- changeset ams:6
CREATE view prueba.v_person
AS
SELECT
id as 'Identificador',
name as 'Nombre',
address1 as 'Dirección 1',
address2 as 'Dirección 2',
city as 'Ciudad'
FROM prueba.person
--rollback DROP VIEW IF EXISTS prueba.v_person
[...]
Para ejecutar los changeset del snippet anterior hay que seguir pasos de ejecución realizados en los ejemplos anteriores.
Creación de tags
Los tags son etiquetas que se definen en un momento determinado para etiquetar qué despliegues se han realizado; por ejemplo, cuando hemos terminado una versión, se puede crear una etiqueta para identificar el punto de la vista de base de datos correspondiente para esa versión.
En Liquibase la creación de una etiqueta es muy sencilla, simplemente hay que ejecutar el comando tag con el número de etiquetado. Un ejemplo puede ser el siguiente:
./liquibase tag --tag=1.0
El resultado en base de datos es la inserción en el campo tag de la tabla DATABASECHANGELOG el valor definido en el atributo tag, en nuestro caso 1.0, correspondiente al registro del último despliegue.
Rollbacks
Un rollback en base de datos consiste en deshacer lo que se ha definido. En una herramienta como Liquibase definir las operaciones de rollback y tener claro las políticas de rollback es un tarea importante y fundamental.
¿Dónde se definen los rollback? Como se ha mostrado en los ejemplos anteriores, los rollback se definen en los changeset de los changelog en la sección –rollback.
¿Hasta qué punto se ejecuta un rollback? Hay dos estrategias, ejecutar el rollback de la última ejecución o bien ejecutar hasta un instante pasado en el tiempo identificado por etiquetas tag.
El comando de ejecución de un rollback hasta un tag, por ejemplo con valor 1.0, es el siguiente:
./liquibase rollback --tag=1.0
El comando de ejecución de un rollback del último despliegue es el siguiente:
./liquibase rollbackCount 1
El resultado del rollback en la tabla DATABASECHANGELOG de la base de datos es la eliminación de los despliegues hasta el tag o bien el último despliegue realizado.
Comandos
Liquibase proporciona otras herramientas que ofrecen información de los despliegues. Estas herramientas lo representan comandos como el comando update. Unas posibles herramientas comunes para ser utilizadas son:
- history.- Permite visualizar el históricos de changeset ejecutados. Para ejecutar este comando se realiza de la siguiente manera: ./liquibase history.
- status.- Permite visualizar el estado de los despliegue realizados. Para ejecutar este comando se realiza de la siguiente manera: ./liquibase status.
Liquibase es una herramienta que permite automatizar las migraciones de esquemas de base de datos permitiendo a los desarrolladores tener controlado los esquemas y datos de las base de datos. Además, de ser una herramienta que puede ser integrada en los procesos de integración continua. La elección de Liquibase o herramientas alternativas como Flyway será en función del equipo, del problema a resolver y las tecnologías empleadas.