En la entrada anterior, NodeRED II: nodos principales, presente el funcionamiento de unos nodos mediante ejemplos. En la presente entrada, NodeRED III: nodo función, me centraré en el nodo función con el cual podremos definir una función definida en código Java Script empleando el nodo Function.
La descripción funcional del conjunto de flujos de trabajo definidos en la entrada son los siguientes:
- Ejemplo 1: función básica.- Definición de un flujo de trabajo con una función básica.
- Ejemplo 2: función y sentencias condicionales.- Definición de un flujo de trabajo con una función en donde se emplean sentencias condicionales.
- Ejemplo 3: función y salidas múltiples.- Definición de un flujo de trabajo con una función de salida múltiple.
- Ejemplo 4: función y bucles.- Definición de un flujo de trabajo con una función en donde se aplican bucles.
- Ejemplo 5: función variables de entorno y trazas.- Definición de un flujo de trabajo con una función en donde se trabaja variables de contexto y trazas.
- Ejemplo 6: función variables de entorno.- Definición de un flujo de trabajo con una función en donde se trabaja con variables de contexto.
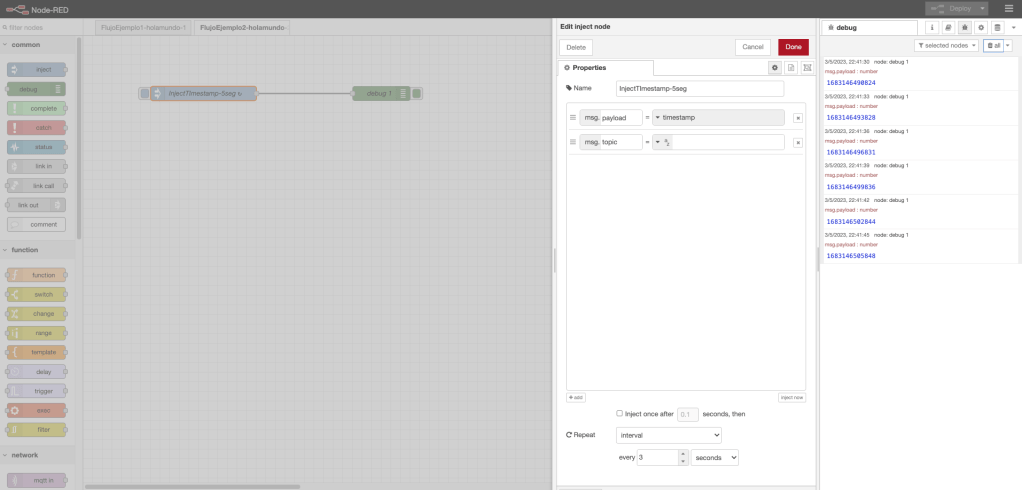
Ejemplo 1: función básica.
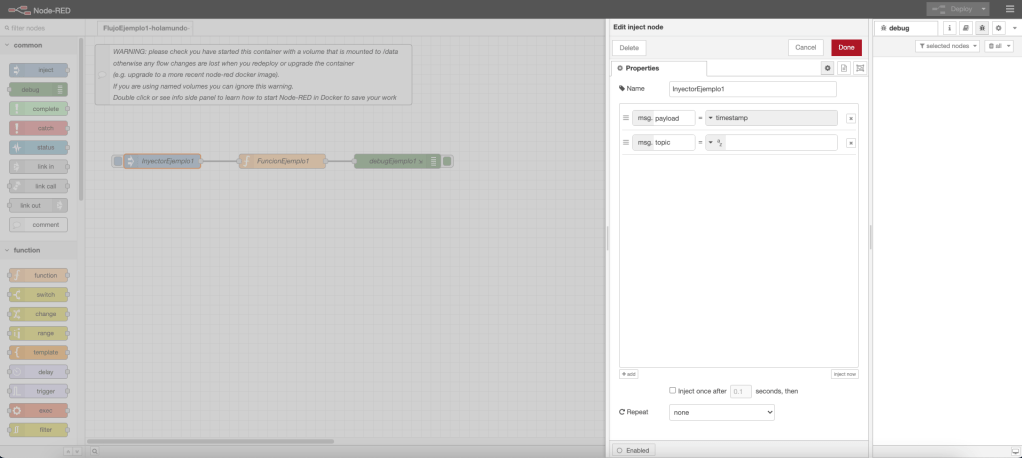
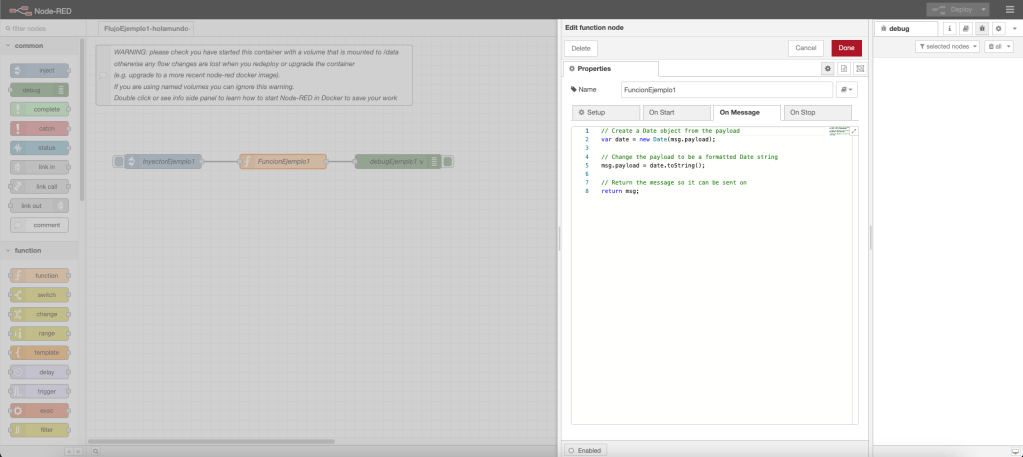
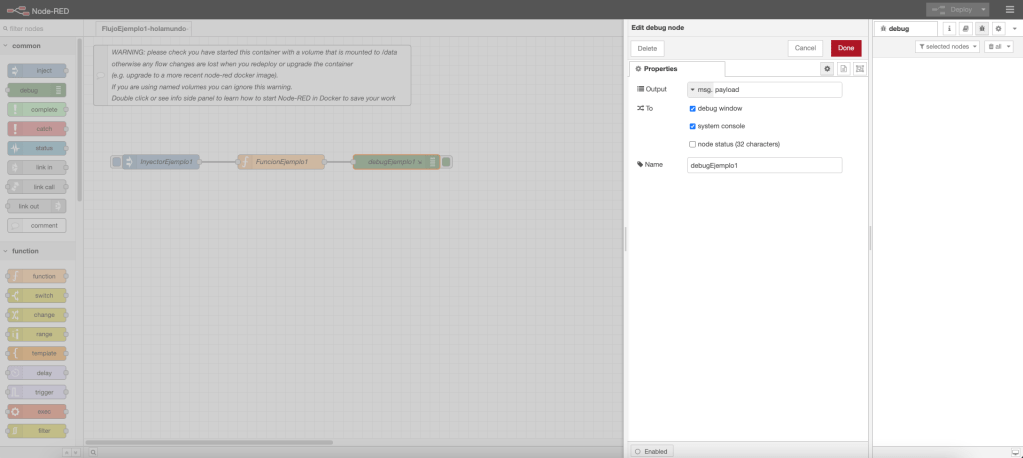
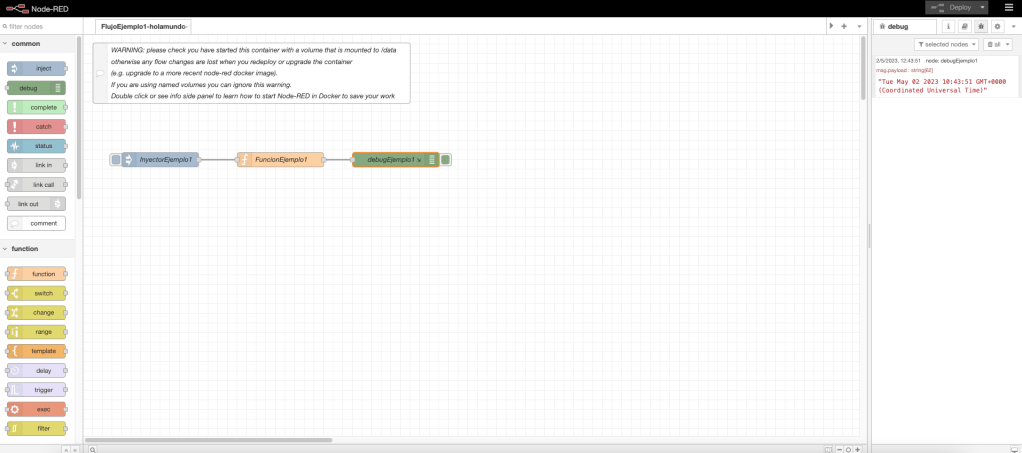
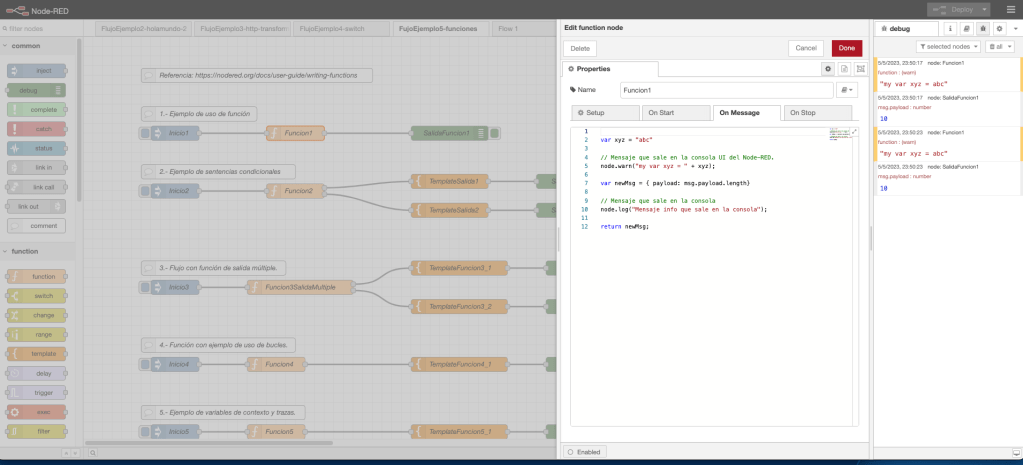
En el flujo de trabajo del ejemplo 1, se define un nodo inyección en donde se inicia el arranque del flujo; se define un nodo función; y, por último, se define un nodo debug para mostrar por consola el resultado y la trazabilidad.
La función del nodo función flujo define una funcionalidad en el evento «On Message», la funcionalidad definida en este evento es muy sencilla: definición de una variable xyx, definición de una variable newMsg, la cual almacena la longitud del string pasado en el objeto msg, y el retorno de la variable msg. La función realiza la escritura de dos trazas en la consola de log: la primera de tipo warning y la segunda de tipo log.
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
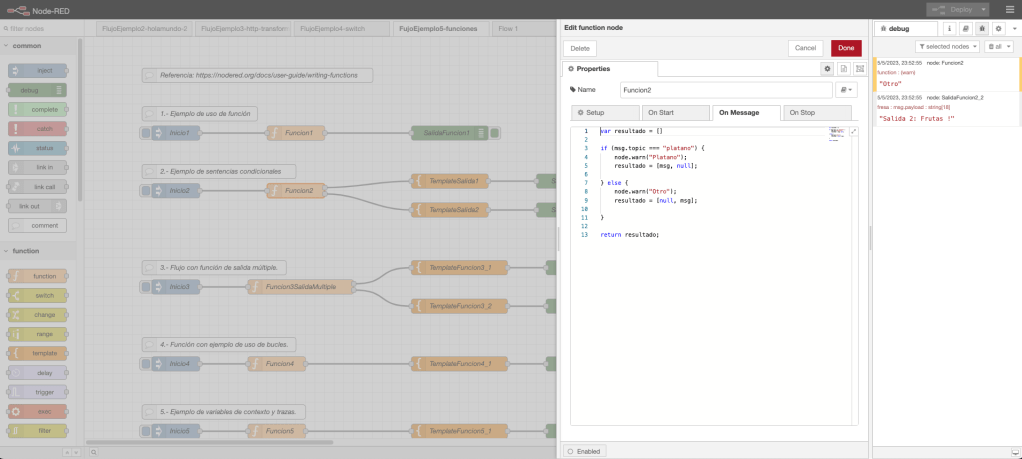
Ejemplo 2: función y sentencias condicionales.
En el flujo de trabajo del ejemplo 2, se define un nodo inyección en donde se inicia el arranque del flujo; se define un nodo función; dos nodos template para procesar la salida; y, por último, dos nodos debug para mostrar por consola el resultado y la trazabilidad de la ejecución.
La funcionalidad del nodo función define una funcionalidad en el evento «On Message», la funcionalidad definida en este evento es la siguiente: definición de una variable de tipo lista; una sentencia condicional la cual asigna un valor para cada condición; dos nodos template para parsear la salida; y, por último, los nodos debug para mostrar por consola el resultado.
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
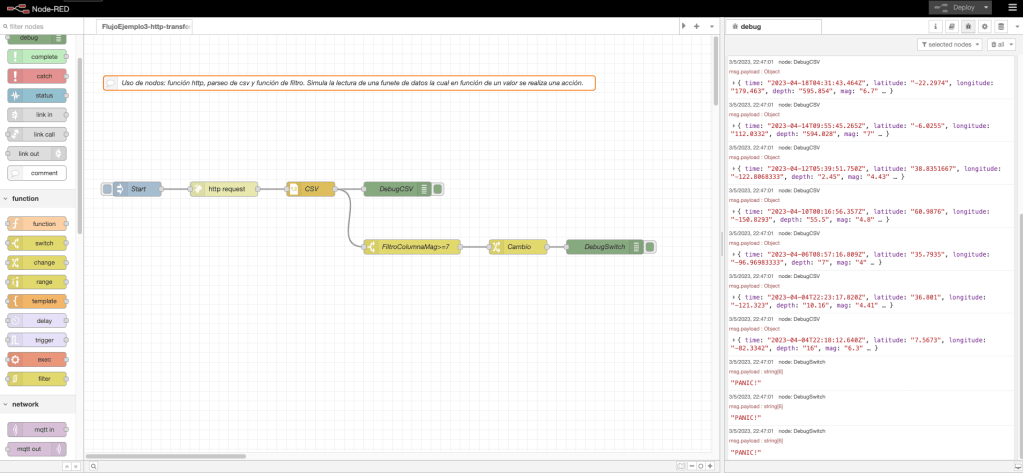
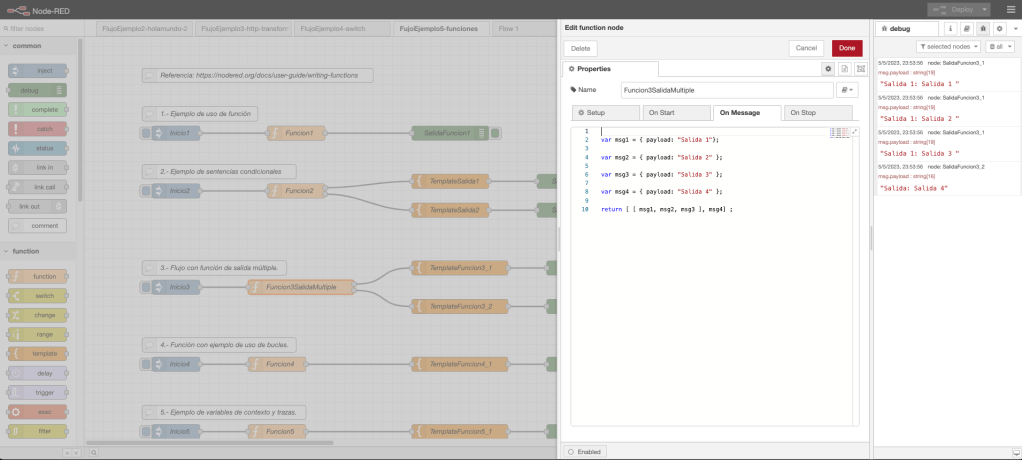
Ejemplo 3: función y salidas múltiples.
En el flujo de trabajo del ejemplo 3, se define un nodo inyección en donde se inicia el arranque del flujo; se define un nodo función; dos nodos template para procesar la salida; y, por último, dos nodos debug para mostrar por consola el resultado y la trazabilidad de la ejecución.
La funcionalidad del nodo función define una funcionalidad en el evento «On Message», la funcionalidad definida en este evento es la siguiente: definición de cuatro variables de tipo diccionario y, como salida, retorno una estructura de tipo lista con las variables definidas.
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
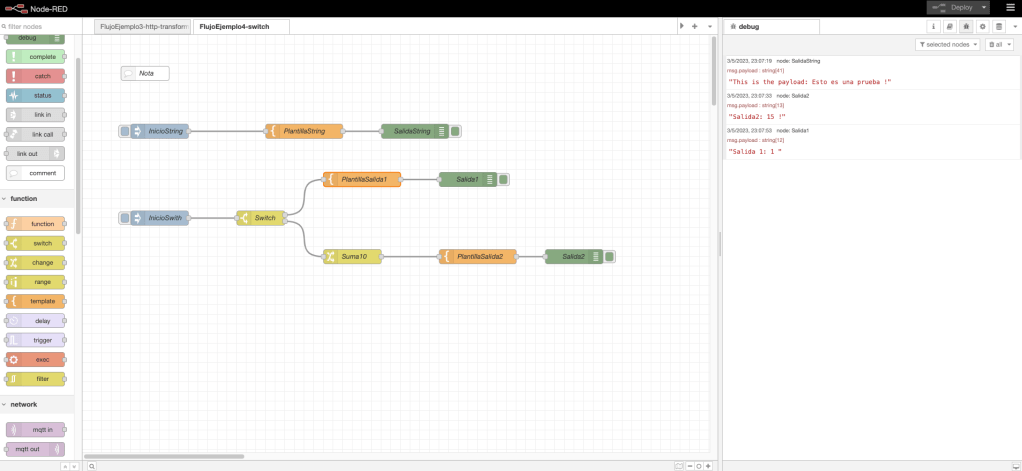
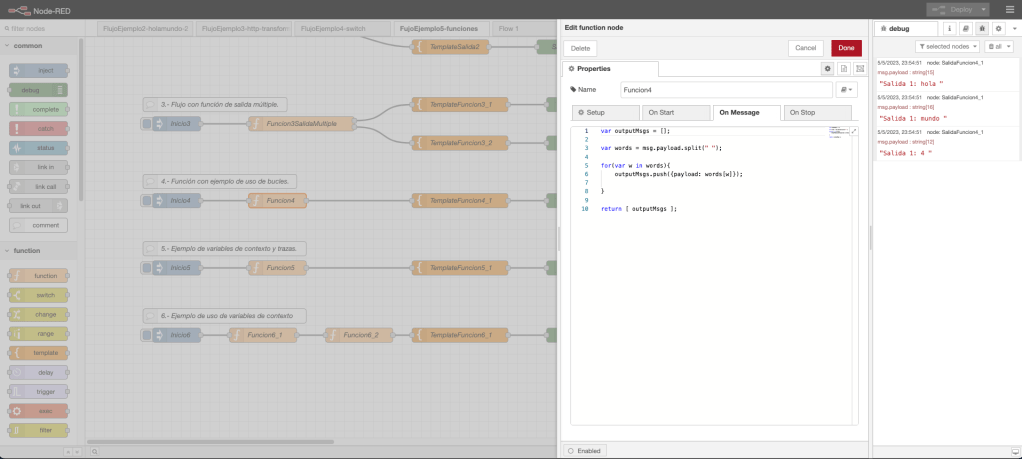
Ejemplo 4: función y bucles.
En el flujo de trabajo del ejemplo 4, se define un nodo inyección en donde se inicia el arranque del flujo; se define un nodo función; un nodo template para procesar la salida; y, por último, dos nodos debug para mostrar por consola el resultado y la trazabilidad de la ejecución.
La funcionalidad del nodo función define una funcionalidad en el evento «On Message», la funcionalidad definida en este evento es la siguiente: definición de un variable de tipo lista, definición de una variable lista con el contenido del string pasado por parámetro, un bucle que recorre las palabras string y, como salida, retorna la estructura con las palabras.
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
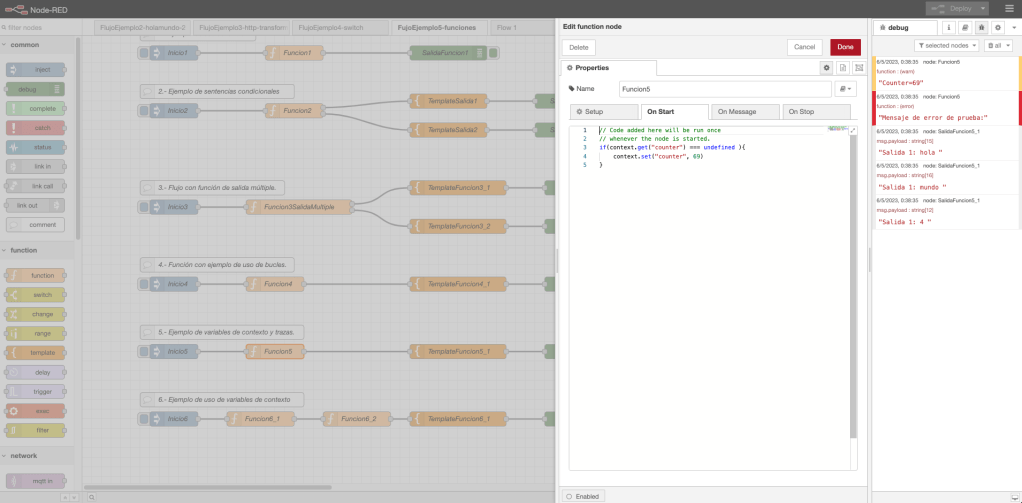
Ejemplo 5: función variables de entorno y trazas.
En el flujo de trabajo del ejemplo 5, se define un nodo inyección en donde se inicia el arranque del flujo; se define un nodo función; un nodo template para procesar la salida; y, por último, dos nodos debug para mostrar por consola el resultado y la trazabilidad de la ejecución.
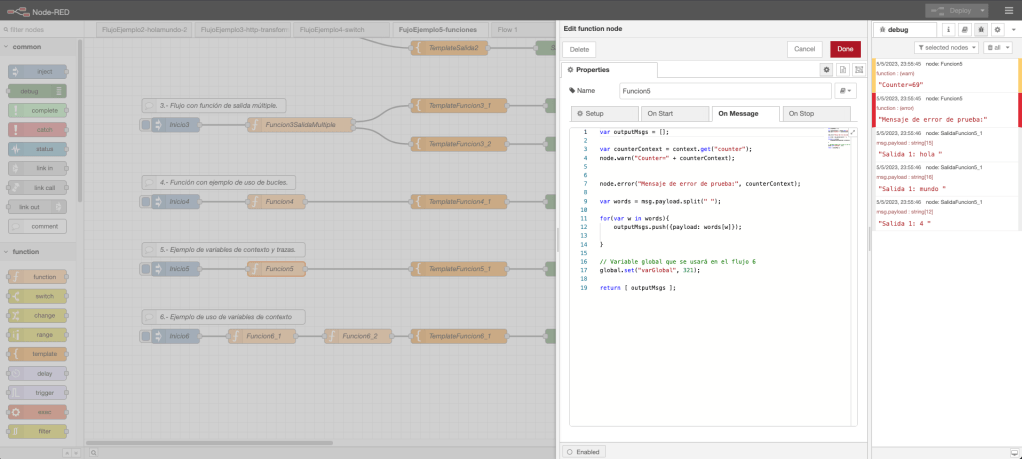
La funcionalidad del nodo función define una funcionalidad en el evento «On Message», la funcionalidad definida en este evento es la siguiente: definición de un variable de tipo lista, definición de una variable lista con el contenido del string pasado por parámetro, un bucle que recorre las palabras string y, como salida, retorna la estructura con las palabras. Además, se muestra por consola el valor de la variable de contexto «counter» y se crea una variable global con nombre «varGlobal» la cual se emplea en el flujo del ejemplo 6. En el evento «On Start», se define la variable de contexto «counter» utilizada en la funcionalidad «On Message».
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
Ejemplo 6: función variables de entorno.
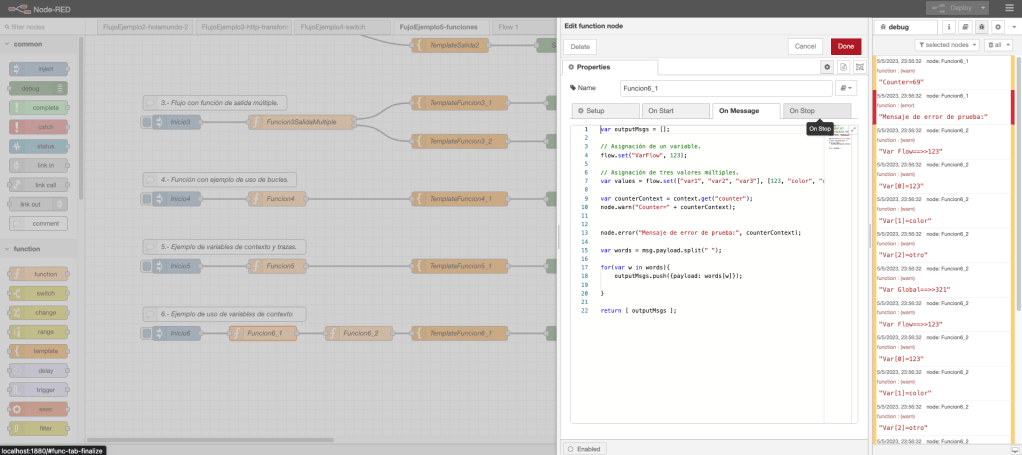
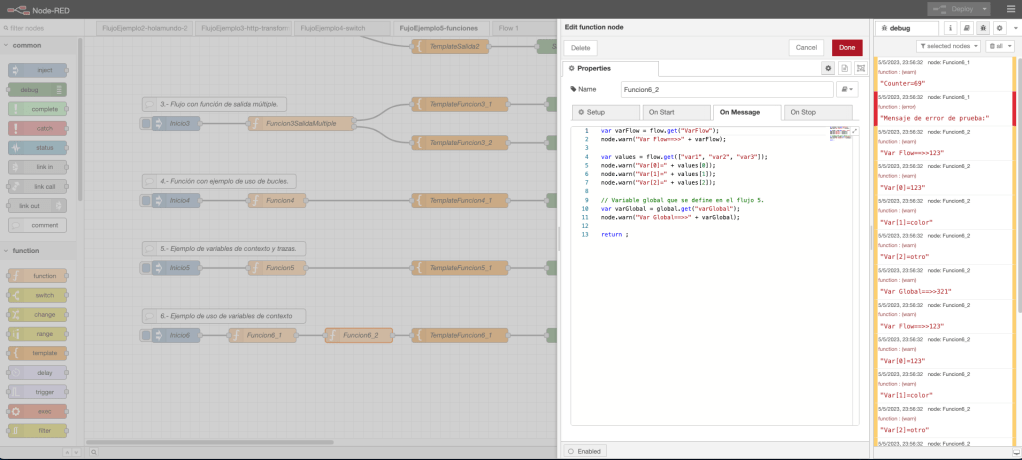
En el flujo de trabajo del ejemplo 6, se define un nodo inyección en donde se inicia el arranque del flujo; se define un par de nodos función; un nodo template para procesar la salida; y, por último, un nodo debug para mostrar por consola el resultado y la trazabilidad de la ejecución.
El primer nodo función es prácticamente igual que el nodo del ejemplo 5 salvo que se muestra la variable de contexto «counter», se definen variables múltiples con nombre values y se define la variable «varFlow». En el segundo nodo función, se muestra por consola las trazas de nivel warning, las variables de contexto y de flujo. Por último, el nodo template aplica una plantilla para retornos al siguiente nodo unstring con el valor del atributo payload del objeto msg y la variable varFlow definida en el flujo.
Desde un punto de vista gráfico, el ejemplo con el código de la función y una ejecución en la consola de NodeRed queda representada en la siguiente imagen de la captura de pantalla del interfaz visual:
Los ejemplos mostrados en la entrada permiten mostrar cómo usar nodos función, algunas características básicas del lenguaje Java Script para la definición de funcionalidad en los nodos función y, además, cómo trabajar con diferentes tipos de entrada y salida con nodos tipo función.
En la siguientes entrada, NodeRED IV: mensajes y secuencias, me centraré en la utilización de mensajes y secuencias de mensajes.