En la presente entrada, Microservicios en Python: plantilla básica, realizaré una descripción de una plantilla base de un microservicio en Python utilizando la librería Flask.
La arquitectura de microservicios es aquel enfoque que permite definir aplicaciones software mediante un conjunto de servicios desplegables de forma independiente, es decir, una aplicación es un conjunto de pequeñas aplicaciones poco acopladas. La definición de microservicio que realiza Martin Fowler es la siguiente:
«El término ‘Arquitectura de microservicio’ ha surgido en los últimos años para describir una forma particular de diseñar aplicaciones de software como conjuntos de servicios desplegables de forma independiente. Si bien no existe una definición precisa de este estilo arquitectónico, existen ciertas características comunes en torno a la organización en torno a la capacidad empresarial, la implementación automatizada, la inteligencia en los puntos finales y el control descentralizado de idiomas y datos.»
El acoplamiento entre los microservicios, se puede realizar utilizando colas, brokers de mensajería o mediante peticiones HTTP. Un ejemplo de un productor y consumidor de mensajes para el broker de mensjaes que contiene Redis pueden ser los que describo en los siguientes enlaces:
- Productor de mensajes en el broker de mensajes Redis.
- Consumidor de mensaje en el broker de mensajes Redis.
La funcionalidad de la plantilla del microservicio es muy simple, se definirá un punto de entrada de tipo POST al cual se le pasarán los campos nombre, operación y operador y, como resultado, retornará un JSON con el resultado. Se empleará la técnica DDD Domain Driven Design para definir una entidad de dominio la cual será almacenda en un supuesto contenedor de datos, en nuestro caso, en memoria.
Las dependencias de las librerías del proyecto se definen en el fichero requirements.txt y contiene las siguientes referencias: flask, dataclasses y pytest.
La arquitectura está compuesta por tres capas horizontales: capa de presentación, representada por el paquete entrypoints; cada de servicios, representada por el paquete services; y, capa de datos, representada por el paquete repository. Desde un punto de vista vertical, tenemos las siguientes capas: capa de dominio, representada por el paquete domain en donde se define las entidades de dominio y DTO; y, por último,capa de excepciones, representado con el paquete exception en cual contiene las excepciones del
aplicativo.

Descripción arquitectónica por capas
Capa de dominio
La capa de dominio está compuesto por el módulo entity_model.py el cual contiene la entidad de dominio UseCaseEntity y los DTO UseCaseRequest y UseCaseResponse. El snippet de la entidad de dominio es el siguiente:
class UseCaseEntity:
def __init__(self,
uuid: str,
name: str,
operation: str,
operator: int,
date_data: Optional[date] = None):
self.uuid = uuid
self.name = name
self.operation = operation
self.operator = operator
self.date = date_data
@property
def calculate(self) -> int:
result = 0
if self.operation == "+":
result = self.operator + self.operator
elif self.operation == "*":
result = self.operator * self.operator
else:
result = -1
return result
Capa de presentación
La capa de presentación está compuesta por el módulo app.py. Los puntos de entrada son: métodos liveness y rediness para conocer el estado del microservicio (en el ejemplo no realizan ninguna operación) y el método para la operación de negocio use_case_example; este método, realiza la obtención de los parámetros de la petición HTTP, creación del DTO de la petición e invocación al método de servicio; para finalizar, retorna el resultado. El snippet de la función es la siguiente:
@app.route("/use_case_example", methods=['POST'])
def do_use_case_example():
"""
use case example
curl --header "Content-Type: application/json" --request POST \
--data '{"name":"xyz1", "operation":"+", "operator":"20"}' \
http://localhost:5000/use_case_example
:return: str
"""
p_name = request.json['name']
p_operation = request.json['operation']
p_operator = int(request.json['operator'])
current_app.logger.info(f"[*] /use_case_example")
current_app.logger.info(f"[*] Request: Name={p_name} operation={p_operation} operator={p_operator}")
current_app.logger.info(f"Name={p_name} operation={p_operation} operator={p_operator}")
data_request = entity_model.UseCaseRequest(uuid=uuid.UUID,
name=p_name,
operation=p_operation,
operator=p_operator)
repository = use_case_repository.UseCaseRepository()
response_use_case = use_case_service.do_something(data_request, repository)
data = jsonify({'result': response_use_case.resul})
return data, 200
Capa de servicio
La capa de servicio está compuesta por el módulo use_case_service.py el cual contiene la función que realiza la operación de negocio: creación de la entidad de dominio, inserción en el repositorio de datos y retorno del resultado. El snippet de la función es el siguiente:
def do_something(request: entity_model.UseCaseRequest,
repository: use_case_repository.AbstractUseCaseRepository) -> entity_model.UseCaseResponse:
"""
Business operation.
:param request: entity_model.UseCaseRequest
:param repository: use_case_repository.AbstractUseCaseRepository
:return: entity_model.UseCaseResponse
"""
if request is None:
raise use_case_exception.UseCaseRequestException()
logging.info(f"[**] /use_case_service.do_something")
entity = entity_model.UseCaseEntity(uuid=request.uuid,
name=request.name,
operation=request.operation,
operator=request.operator,
date_data=date.today())
repository.add(entity)
return entity_model.UseCaseResponse(str(entity.calculate))
Capa de repositorios
La capa de repositorio define el respositorio en donde se almacenan los datos la cual está compuesta por el módulo use_case_repository.py. El módulo contiene la definición del repositorio UseCaseRepository para la entidad UseCaseEntity y la clase de abstracta con las operaciones de los repositorios. El snippet del repositorio es el siguiente:
class UseCaseRepository(AbstractUseCaseRepository):
"""
Definition of the operations that connect to database.
"""
def __init__(self) -> None:
self.database: [entity_model.UseCaseEntity] = []
def add(self, entity: entity_model.UseCaseEntity) -> bool:
result: bool = False
logging.info(f"[***] /use_case_repository.add")
if entity is not None:
result = True
self.database.append(entity)
return result
def get(self, p_uuid: str) -> entity_model.UseCaseEntity:
index = 0
enc = False
result: entity_model.UseCaseEntity = None
logging.info(f"[***] /use_case_repository.get")
while (index < len(self.database)) and not enc:
aux: entity_model.UseCaseEntity = self.database[index]
if aux.uuid == uuid.UUID(p_uuid):
result = aux
enc = True
index += 1
return result
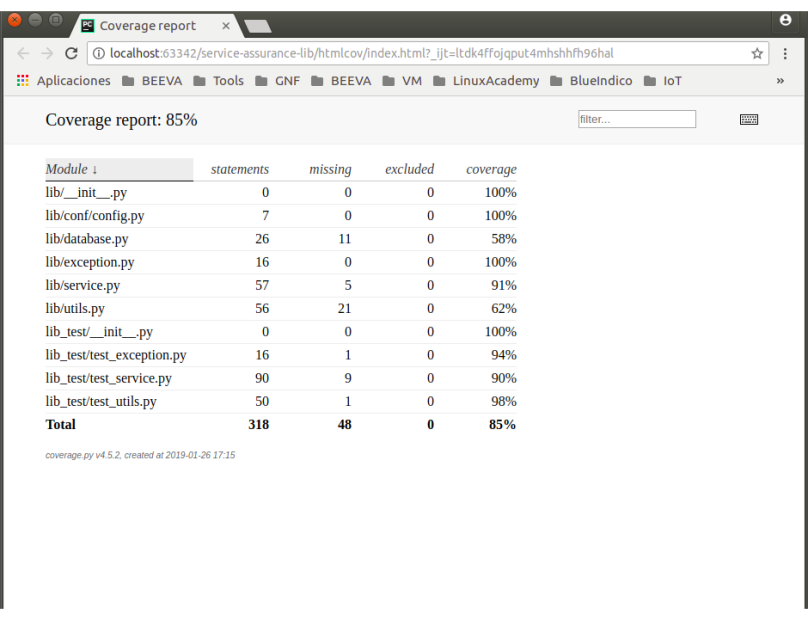
Pruebas
La plantilla contiene el directorio tests el cual contiene los test de la plantilla del microservicio. Para ejecutar los test se ejecuta el siguiente comando desde la carpeta raíz del proyecto:
>pytest --setup-show
Docker
Todo microservicio debe de tener la definición de la imagen para que sea ejecutado en un contenedor. Así, existe el fichero Dockerfile para definir dicha imagen. El contenido de la imagen contiene las operaciones de instalación de las herramientas para Python, instalación de las librerías, copiado de código fuente y variables de entorno y ejecutación. El snippet con el contenido del DOckerfile es el siguiente:
FROM python:3.8-alpine RUN apk add --no-cache --virtual .build-deps gcc musl-dev python3-dev RUN apk add libpq COPY requirements.txt /tmp RUN pip install -r /tmp/requirements.txt RUN apk del --no-cache .build-deps RUN mkdir -p /app COPY . /app/ WORKDIR /app ENV FLASK_APP=entrypoints/app.py FLASK_DEBUG=1 PYTHONUNBUFFERED=1 CMD flask run --host=0.0.0.0 --port=80
Makefile
Para facilitar las operaciones de Docker, se ha definido un fichero de tipo Makefile en el cual se definen las operaciones necesarias para operar con Docker. Las operaciones son las siguientes:
- Operación build.- Creación de la imagen. Para ejecutar la operación se ejecuta el comando make build desde la raíz del proyecto. El snippet de la definición de la operación build es la siguiente:
build:
docker image build -t alvaroms/template-microservice:v1.0 .
- Operación run.- Arranque de un contenedor con la imagen del proyecto. Para ejecutar la operación se ejecuta el comando make run desde la raíz del proyecto. El snippet de la definición de la operación run es la siguiente:
run: docker container run -d --name template-microservice -p 6060:80 alvaroms/template-microservice:v1.0
- Operación exec.- Acceso a la consola del contenedor. Para ejecutar la operación se ejecuta el comando make exec desde la raíz del proyecto. El snippet de la definición de la operación exec es la siguiente:
exec:
docker container exec -it template-microservice /bin/sh
- Operación logs.- Visualización de los logs del contenedor. Para ejecutar la operación se ejecuta el comando make logs desde la raíz del proyecto. El snippet de la definición de la operación logs es la siguiente:
logs:
docker container logs template-microservice
- Operación test.- Ejecución de los test. Para ejecutar la operación se ejecuta el comando make test desde la raíz del proyecto. El snippet de la definición de la operación test es la siguiente:
test:
pytest --setup-show
- Operación all.- Ejecución de los test, construcción de la imagen y arranque del contenedor. Para ejecutar la operación se ejecuta el comando make all desde la raíz del proyecto. El snippet de la definición de la operación test es la siguiente:
all: test build run
Pruebas del API
Los comando curl para realizar las pruebas sobre el microservicio desplegado en el contenedor son los siguientes:
- Root del microsercicio.
curl http://localhost:6060/
- Función rediness
curl http://localhost:6060/readiness
- Función liveness
curl http://localhost:6060/liveness
- Función de negocio.
curl --header "Content-Type: application/json" --request POST \ --data '{"name": "xyz1", "operation": "+", "operator": "20"}' \ http://localhost:6060/use_case_example
Integración Contínua
Para finalizar, se define un pipeline de integración contínua definida en el fichero .travis.yml. El snippet con el contenido es el siguiente:
dist: xenial language: python python: 3.6 install: - pip3 install -r requirements.txt script: - make test branches:
Para el lector interesado puede acceder al código a través del siguiente enlace.