En la presente entrada, NodeRED I: Instalación, realizaré una descripción de la herramienta NodeRed y explicaré los primeros pasos para utilizar NodeRED mediante la definición de un programa básico representado en un flujo NodeRED.
Node-RED es aquella herramienta de programación que permite la conexión de dispositivos hardware, API y servicios online.
El editor de Node-RED está basado en una herramienta gráfica que se accede desde el navegador web La estructura de la interfaz gráfica está compuesta en la parte central por un panel de trabajo; en la parte izquierda, se muestra los diferentes nodos funcionales categorizados por funcionalidades; y, en la parte derecha, un conjunto de pantallas en donde se puede visualizar diferentes paneles de información.
Un programa de NodeRED es aquella estructura visual de un flujo de operaciones compuesta por la unión de nodos la cual realiza una funcionalidad determinada a partir de los datos de entrada definidos en los nodos para tal fin y, como salida, un resultado determinado en los nodos de salida.
Instalación en Docker
NodeRED puede ser instalado en varias plataformas: en una máquina local, en un contenedor docker, en un dispositivo como puede ser una placa Raspberry o bien en un servicio en la nube como AWS o Azure. En el caso que presento, describiré los pasos que he seguido para utilizar NodeRED en un contenedor Docker.
Para realizar la descarga de la imagen de Docker con la instalación de NodeRED, ejecuté el siguiente comando:
docker pull nodered/node-red
Para realizar el arranque de NodeRED con la imagen descargada, ejecutaré el siguiente comando desde la línea de comandos:
docker run -it -p 1880:1880 -v node_red_data:/data --name mynodered nodered/node-red
Una segunda forma para arrancar NodeRED en Docker es identificando el volumen externo del contenedor con una carpeta del sistema de ficheros de la máquina en donde levanta. Para realizar este arranque, identificamos el path de la carpeta de la siguiente forma:
docker run -it -p 1880:1880 -v /path/to/folder:/data --name mynodered nodered/node-red
La descripción de los parámetros del comando anterior son las siguientes:
- -it.- Modo de arranque del contenedor.
- -p 1880:1880.- Acceso al interfaz gráfico del contenedor por el puerto 1880.
- -v node_red_data:/data.- Creación de un volumen de datos a la carpeta de configuración de datos de NodeRED con el nombre /data.
- –name mynodered.- Asignación del nombre del contenedor con nombre mynodered.
- nodered/node-red.- Nombre de la imagen docker que se emplea en el contenedor.
Para verificar si el contenedor se ha levantado correctamente, se ejecuta el siguiente comando desde la línea de comandos:
docker container ps -a
Para acceder a la interfaz gráfica del editor de NodeRED una vez arrancado el contenedor, se abre una ventana de un navegador y se utiliza la siguiente URL: localhost:1880. El aspecto visual del editor queda representado en la siguiente imagen:

Ejemplo básico
Para definir un programa en NodeRED, se realiza la definición de un flujo de nodos en el panel de trabajo central con los nodos existentes en la paleta de nodos existentes en la parte izquierda del interfaz. El proceso se realiza seleccionando y arrastrando los nodos y enlazando dichos nodos.
Las categorías de los nodos en NodeRED son las siguientes:
- Categoría common.- Nodos en donde definen funcionalidades comunes como; por ejemplo: inyección de un valor, operación de debug.
- Categoría function.- Nodos en donde definen funciones de usuario, funciones de control de flujo,…
- Categoría network.- Nodos en donde se definen operaciones de red; por ejemplo: peticiones MQTT o bien HTTP, entre otras.
- Categoría sequences.- Nodos en donde se definen operaciones sobre secuencias de flujo.
- Categoría parser.- Nodos en donde se definen operaciones de parseo de tipos de datos.
- Categoría storage.- Nodos en donde se definen operaciones de almacenamiento.
Para desplegar y verificar el correcta definición, es necesario pulsar al botón «Deploy» ubicado en la parte superior derecha.
Un ejemplo básico tipo «Hola Mundo» consiste en inyectar un dato, como por ejemplo, el valor de una fecha determinada; procesar dicho valor en una función y, por último, mostrarlo por la consola debug.
El flujo se compondrá por los siguiente nodos: el primero, un nodo de tipo common de tipo inject el cual inyecta un valor; el segundo, un nodo tipo función el cual, el valor que recibe como parámetro de entrada, lo procesará y retornará para el siguiente nodo; y, por último, un nodo de tipo debug el cual realiza la escritura del valor inyectado.
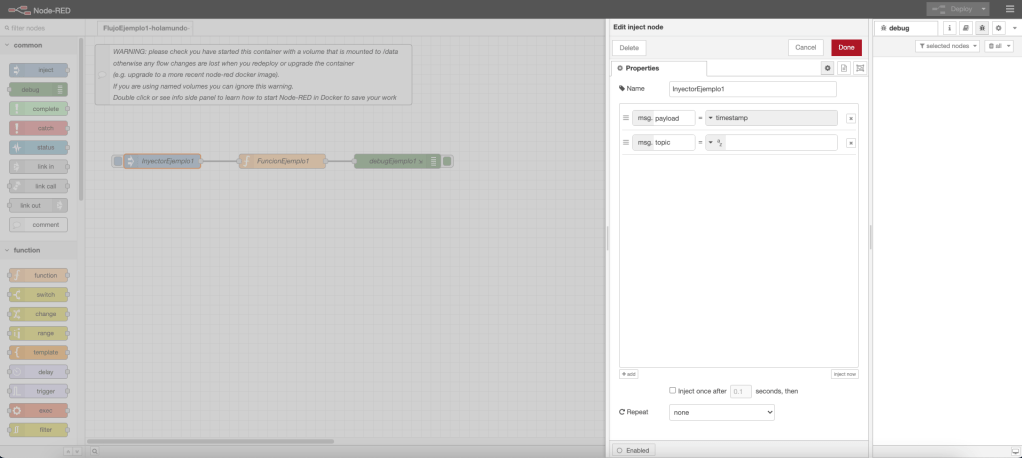
Nodo inyector
El nodo inyector es aquel nodo que está compuesto por un objeto msg compuesto de dos atributos: payload, con el valor timestamp que se inyecta; y, topic, con el mensaje adicional a inyectar. El aspecto visual del componente es el siguiente:
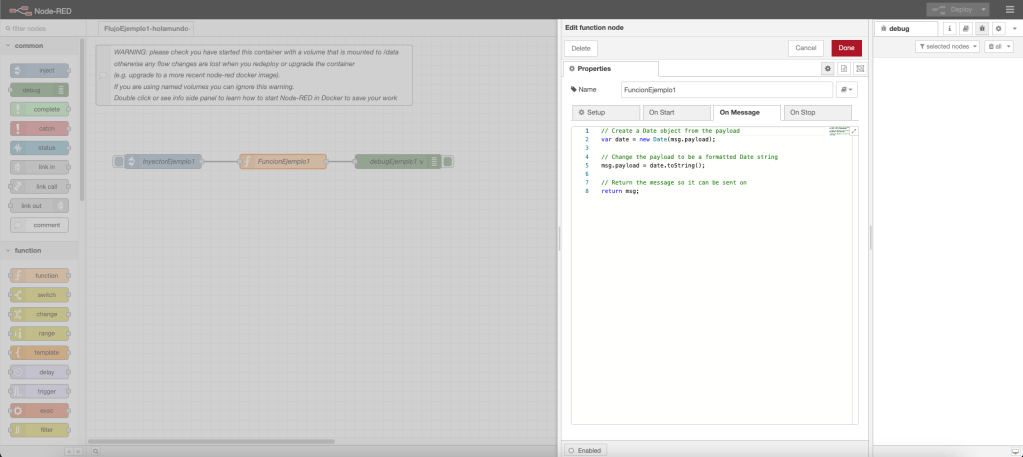
Nodo Function
El nodo función es aquel nodo el cual gestiona distintos eventos los cuáles pueden ser: evento On Start, funcionalidad que se realiza al inicio del nodo; evento On Message, funcionalidad que se ejecuta al recibir un mensaje; y, evento On Stop, fncionalidad que se realiza al parar el nodo. Todo la funcionalidad se define en Java Script.
En nuestro ejemplo, se define la funcionalidad de evento al recibir un mensaje la cual realiza el tratamiento del valor timestamp recibido y su transformación en tipo String. El aspecto visual del componente es el siguiente:
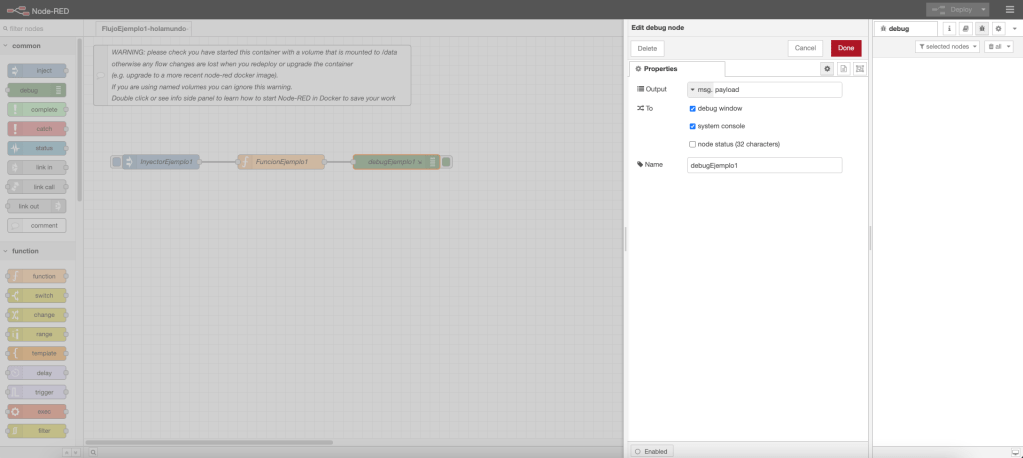
Nodo Debug
El nodo debug es aquel que escribe en la consola el campo del mensaje especificado. El aspecto visual del componente es el siguiente:
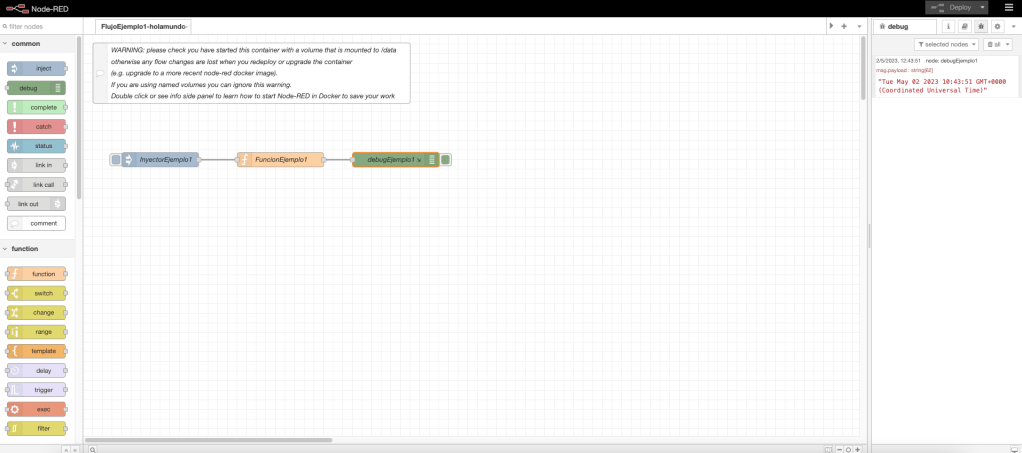
Para ejecutar el flujo de trabajo es necesario pulsar en el cuadro izquierdo ubicado en el nodo inject. El aspecto de la salida en la consola del ejemplo descrito es el siguiente:
Obtención de la configuración y flujos de trabajo.
La definición de los flujos de trabajo que se definen de forma visual, representados en el fichero flows.json, así como la configuración de NodeRED, representado en el fichero settings.js, se encuentra en la carpeta data del contenedor y en el volumen de Docker. Una forma sencilla para realizar una copia de la carpeta data, es utilizando el comando docker de copiado. Así, para realizar una copia de la carpeta data del contenedor utilizado mynodered a una carpeta determinada, se puede emplear el siguiente comando:
docker cp mynodered:/data /your/backup/directory
En las siguiente entrada, NodeRED II: nodos principales, iré profundizando en la definición de flujos y usos de NodeRED.
